library(dplyr)Resumiendo datos
Resumir nuestros datos suele ser el primer paso en la exploración de datos y es necesario para comprender los patrones en la magnitud y variabilidad de nuestras mediciones.
Utilizaremos el paquete dplyr, que tiene muchas funciones convenientes para resumir datos, así que comencemos cargando el paquete.
Al igual que en la página de ayuda sobre Subconjunto de datos, utilizaremos un conjunto de datos en el que se muestrearon murciélagos en un bosque en regeneración del sureste de Australia que se había adelgazado para reducir la densidad de árboles. Descarga el conjunto de datos, Bats_data.csv, e impórtalo en R.
Bats <- read.csv(file = "Bats_data.csv", header = T, stringsAsFactors = F)Resumir datos con dplyr
Obtener medidas resumidas de una sola variable
Podemos usar la función summarise con una variedad de funciones resumen incorporadas de R para obtener estadísticas resumidas de nuestros datos.
Por ejemplo, para obtener la actividad media de los murciélagos en todas las mediciones nocturnas del estudio, usaría la función de resumen mean dentro de la función summarise de la siguiente manera, especificando el marco de datos (Bats), la variable de la que quiero obtener la media (Activity) y un nombre para la nueva variable (Mean.Activity):
summarise(Bats, Mean.Activity = mean(Activity)) Mean.Activity
1 316.0405Podemos agregar tantas otras medidas como deseemos, incluyendo una amplia gama de funciones resumen (descritas con #).
summarise(Bats,
mean.activity = mean(Activity), # media
min.Activity = min(Activity), # mínimo
max.Activity = max(Activity), # máximo
med.Activity = median(Activity), # mediana
sd.Activity = sd(Activity), # desviación estándar
var.Activity = var(Activity), # varianza
n.Activity = n(), # tamaño de la muestra
se.Activity = sd.Activity / sqrt(n.Activity), # error estándar
IQR.Activity = IQR(Activity) # rango intercuartílico
) mean.activity min.Activity max.Activity med.Activity sd.Activity var.Activity
1 316.0405 9 1070 282 203.1081 41252.89
n.Activity se.Activity IQR.Activity
1 173 15.44202 292Si estamos analizando factores, especialmente si están ordenados de alguna manera, es posible que algunas de las otras funciones resumen de dplyr sean útiles. Por ejemplo:
summarise(Bats,
first.site = first(Site), # primer valor en la variable Site
last.Site = last(Site), # último valor en la variable Site
third.Site = nth(Site, 3), # valor n-ésimo de Site
n.Sites = n_distinct(Site) # número de sitios distintos
) first.site last.Site third.Site n.Sites
1 CC02A1 KC33A2 CC02A1 47Obteniendo medidas resumidas de grupos de filas
Muy a menudo estamos interesados en mediciones de valores promedio y variabilidad en diferentes categorías, por lo que necesitamos calcular medidas resumidas para variables dentro de cada categoría. Por ejemplo, en este conjunto de datos, es posible que deseemos comparar la actividad de murciélagos en diferentes bosques que varían en su historial de adelgazamiento. Los sitios pertenecen a cuatro categorías de historial de adelgazamiento: sitios de crecimiento denso que fueron adelgazados recientemente (“a corto plazo”) y a medio plazo (“a medio plazo”), sitios que nunca fueron adelgazados (“sin adelgazar”) y bosques abiertos maduros (“referencia”).
Para resumir cualquier variable para cada una de estas categorías, utilizamos la función group_by en dplyr.
Bats_by_Treatment <- group_by(Bats, Treatment.thinned)En orden de conservar nuestro conjunto de datos original tal como está, he utilizado la función para crear un nuevo conjunto de datos llamado “Bats_by_Treatment”. Ahora puedo utilizar exactamente el mismo código que usamos anteriormente para resumir los datos para cada uno de los grupos.
Treatment.summary <- summarise(Bats_by_Treatment,
mean.Activity = mean(Activity), # media
min.Activity = min(Activity), # mínimo
max.Activity = max(Activity), # máximo
med.Activity = median(Activity), # mediana
sd.Activity = sd(Activity), # desviación estándar
var.Activity = var(Activity), # varianza
n.Activity = n(), # tamaño de la muestra
se.Activity = sd.Activity / sqrt(n.Activity), # error estándar
IQR.Activity = IQR(Activity) # rango intercuartílico
)Ten en cuenta que el marco de datos de entrada ahora es “Bats_by_Treatment”, en lugar de “Bats”.
Los nuevos datos resumidos se han colocado en un nuevo objeto (Treatment.summary), que pertenece a la clase “tbl” específica de dplyr. Para convertir esto a la clase de marco de datos más ampliamente utilizada, podemos usar as.data.frame.
Treatment.summary <- as.data.frame(Treatment.summary)Visualiza este nuevo marco de datos para ver las estadísticas resumidas para cada una de las cuatro categorías de bosque.
View(Treatment.summary)También puedes combinar el agrupamiento y la sumarización en un código más ordenado utilizando el operador de tubería %>%. Por ejemplo, el código anterior podría reemplazarse por:
Treatment.summary <- Bats %>%
group_by(Treatment.thinned) %>%
summarise(
mean.Activity = mean(Activity), # media
min.Activity = min(Activity), # mínimo
max.Activity = max(Activity), # máximo
med.Activity = median(Activity), # mediana
sd.Activity = sd(Activity), # desviación estándar
var.Activity = var(Activity), # varianza
n.Activity = n(), # tamaño de la muestra
se.Activity = sd.Activity / sqrt(n.Activity), # error estándar
IQR.Activity = IQR(Activity) # rango intercuartílico
) Problemas con datos faltantes
Las cosas pueden salir mal en el campo y no siempre recopilamos todos los datos que necesitamos en cada sitio.
Para mostrarte cómo esto afecta a la función summarise, podemos crear una nueva variable (Activity2), que es una copia de Activity pero con algunos de los datos de actividad (las primeras cuatro filas) ahora faltantes.
Bats$Activity2 <- Bats$Activity
Bats$Activity2[1:4] <- rep(NA, 4)A continuación, intentemos resumir los datos:
summarise(Bats, mean.Activity = mean(Activity2)) mean.Activity
1 NAVerás que obtenemos un NA como resultado. Para obtener la media de todos los valores que están presentes, podemos agregar un argumento, na.rm=TRUE, para eliminar las filas que son NA.
summarise(Bats, mean.Activity = mean(Activity2, na.rm = TRUE)) mean.Activity
1 314.8757Justo recuerda que esto disminuirá el tamaño de tu muestra. Esto funcionará para las funciones de resumen, excepto para la función n que cuenta el número de valores en un vector. Para contar los datos no faltantes, puedes usar este fragmento de código (un poco más complicado) para obtener el nuevo tamaño de muestra.
length(Bats$Activity2[!is.na(Bats$Activity2)])[1] 169Esto calcula el número de valores, length, del vector de valores de actividad de murciélagos, Bats$Activity2, donde no son NA, !is.na. Revisar Subsetting data puede ayudarte a entender esta afirmación.
Comunicando los resultados
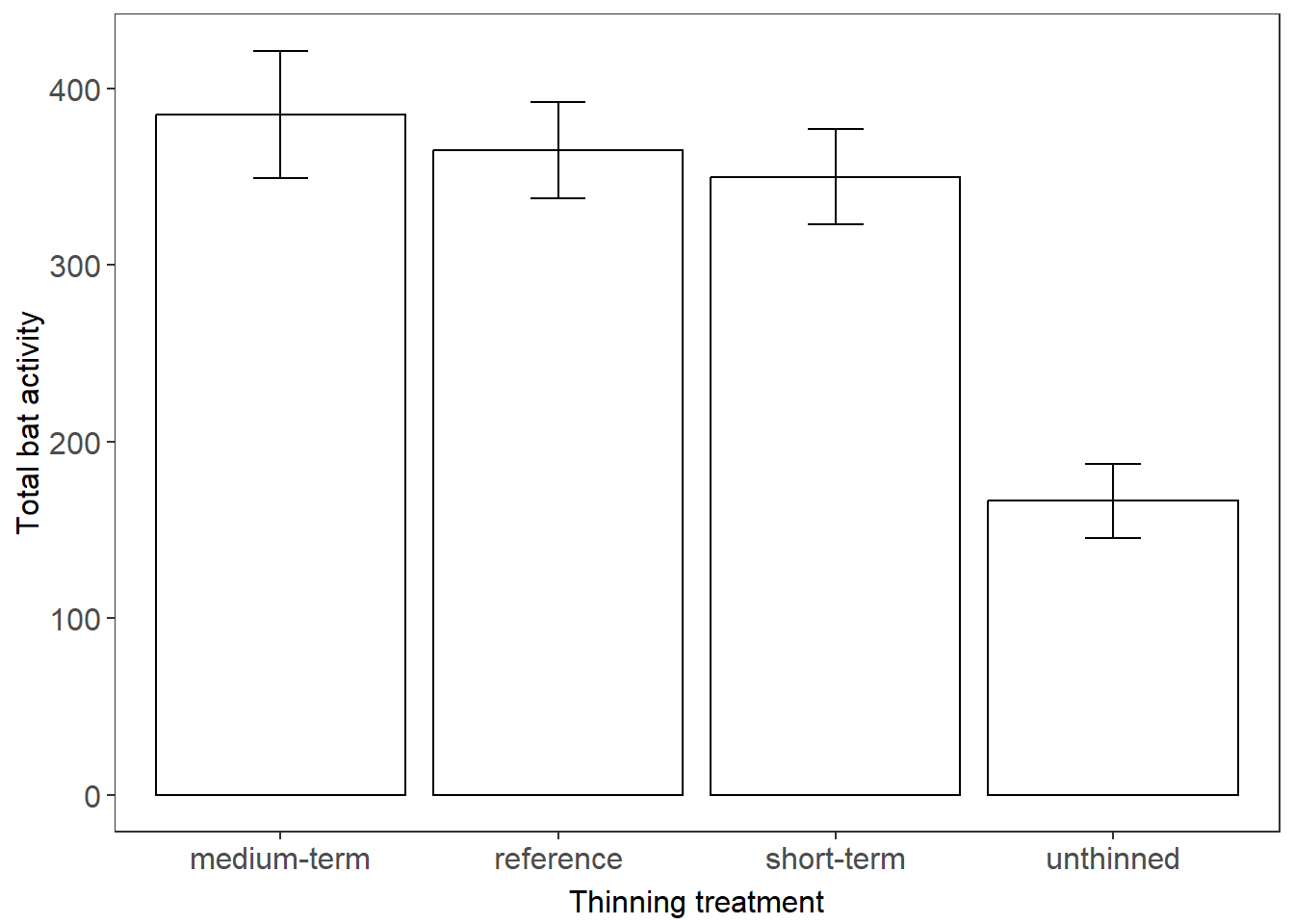
Escrito Si estuviéramos escribiendo un artículo sobre la actividad de murciélagos en diferentes tratamientos de adelgazamiento forestal, podríamos usar nuestros datos resumidos para hacer algunas observaciones generales al comienzo de nuestra sección de resultados, antes de un análisis más profundo. Por ejemplo: “Los murciélagos fueron dos veces más activos en bosques maduros abiertos (referencia) (365 ? 27) en comparación con el crecimiento regenerado no adelgazado (166 ? 21) (media ? EE). Sin embargo, la actividad de los murciélagos fue similar en los bosques adelgazados a mediano plazo (385 ? 36) y a corto plazo (350 ? 27) y en los bosques de referencia”.
Visual Presentar medias y errores estándar de datos categóricos nos brinda una forma de comunicar visualmente un efecto del tratamiento (siempre y cuando esté respaldado por un análisis estadístico adecuado). Aquí hemos utilizado el paquete ggplot2 para crear un gráfico de barras simple con medias ? error estándar (barras de error).
Ayuda adicional
Este tutorial se basó en el excelente Data wrangling with dplyr and tidyr cheat sheet producido por Rstudio. Las imágenes fueron obtenidas del mismo documento.
Puedes escribir ?dplyr para obtener ayuda con este paquete.
Si deseas aprender más sobre el lenguaje ggplot para graficar, echa un vistazo a nuestras hojas de trabajo sobre gráficos, comenzando con Plotting with ggplot: the basics.
Autor: Rachel V. Blakey
Año: 2016
Última actualización: Ene. 2026