pt(q, df = your.df, lower.tail = FALSE) * 2T-test emparejado
Los t-tests emparejados se utilizan para comparar las medias de dos grupos de medidas cuando los objetos individuales se miden dos veces, una vez para cada tipo de medida. Los datos pueden estar emparejados de varias formas: si se toma la misma medida de un objeto individual en dos tratamientos diferentes o en dos momentos diferentes, o si se contrastan diferentes tipos de medidas del mismo objeto.

Por ejemplo, para contrastar el rendimiento fotosintético de diez plantas en dos entornos de un invernadero (sombreado y soleado), podríamos medir el rendimiento en cada planta individual dos veces, una vez a la sombra y otra vez al sol. Las medidas están emparejadas por pertenecer a la misma planta individual.
Para este diseño experimental, utilizaríamos un t-test emparejado para comparar las mediciones realizadas en los dos entornos. Las 20 mediciones individuales no son independientes entre sí, porque esperaríamos que el par de mediciones tomadas de la misma planta individual sean más similares entre sí que si se tomaran al azar de todas las plantas disponibles. Por lo tanto, no podemos utilizar un t-test de muestras independientes - ese test sería apropiado si cada planta se utilizara solo una vez, con algunas plantas medidas en el tratamiento de sombra y un conjunto diferente de plantas medidas en el tratamiento soleado.
Emparejar datos de esta manera se hace generalmente para reducir la variación probable entre las mediciones con el objetivo de detectar mejor las diferencias entre los grupos. En este ejemplo, la diferencia entre las dos medidas de rendimiento fotosintético en una planta determinada debería reflejar principalmente el efecto de la luz solar, mientras que en un diseño de muestras independientes, la diferencia entre una planta a la sombra y otra planta al sol reflejará tanto las diferencias en los efectos de la luz solar como las diferencias entre las plantas individuales.
Para un t-test emparejado, la estadística de prueba, t, es:
\[t = \frac{\bar{d}}{SE_{d}}\]
Donde \(\bar{d}\) es la media de las diferencias entre los valores de cada par, y SEd es el error estándar de ese conjunto de diferencias.
Cabe destacar que esta ecuación es idéntica a un t-test de muestra única, utilizado para contrastar cualquier media de muestra (\(\bar{x}\)) con una media poblacional conocida (\(\mu\)) o un valor hipotético. Lo que estás haciendo aquí es probar si tu muestra de diferencias probablemente proviene de una población de diferencias que tienen una media de cero (otra forma de decir que tus grupos son iguales).
\[t = \frac{\bar{x}-\mu}{SE}\]
Ejecución del análisis
El estadístico de prueba t es relativamente sencillo de calcular manualmente. Luego, se puede verificar el estadístico de prueba con una distribución t para determinar la probabilidad de obtener ese valor del estadístico de prueba si la hipótesis nula es cierta. En R, para calcular la probabilidad asociada a un valor dado de t, utiliza:
where q es tu valor de t, your.df es el número de grados de libertad (el número de pares - 1). El argumento lower.tail = FALSE asegura que estás calculando la probabilidad de obtener un valor de t mayor que el tuyo (es decir, la cola superior, P[X > x]). Ten en cuenta que el valor crítico para t (\(\alpha = 0.05\)) varía dependiendo del número de grados de libertad: mayores grados de libertad = menor valor crítico de t.
La función t.test te proporciona el estadístico de prueba y su probabilidad asociada en una única salida. Para un t-test emparejado, usaríamos:
t.test(x = my_sample1, y = my_sample2, paired = TRUE)where my_sample1 y my_sample2 son vectores que contienen las mediciones de cada muestra. Debes asegurarte de que los dos vectores tengan el mismo número de valores y de que los datos de cada par estén en las filas correspondientes.
Alternativamente, si tienes un marco de datos con las variables de respuesta y predictor en columnas separadas, puedes utilizar una fórmula y ~ x en lugar del código anterior. Nuevamente, debes asegurarte de que los pares coincidentes estén en el orden correcto (por ejemplo, la cuarta fila del tratamiento sombreado corresponde a los datos recopilados de la misma planta que la cuarta fila del tratamiento soleado).
Descarga un conjunto de datos de ejemplo en este formato, Greenhouse.csv, e impórtalo en R.
Greenhouse <- read.csv(file = "Greenhouse.csv", header = TRUE)El t-test emparejado se realiza con la función t.test, con los argumentos que especifican la variable de respuesta (Performance) a la izquierda de ~, la variable predictora (Treatment) a la derecha de ~, el marco de datos a utilizar y el hecho de que es un t-test emparejado.
t.test(Performance ~ Treatment, data = Greenhouse, paired = TRUE)Interpretación de los resultados
Paired t-test
data: shady_vals and sunny_vals
t = -18.812, df = 9, p-value = 1.557e-08
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-0.2111674 -0.1658326
sample estimates:
mean difference
-0.1885 El resultado importante de una prueba t pareada incluye la estadística de prueba t, en este caso 18.8, los grados de libertad (en este caso 9) y la probabilidad asociada con ese valor de t. En este caso, tenemos un valor de p muy bajo (p < 0.001) y podemos rechazar la hipótesis nula de que las plantas puedan realizar la fotosíntesis con el mismo rendimiento en los dos entornos de luz.
También se obtienen la media y los intervalos de confianza del 95% para las diferencias entre las mediciones de cada par (estos no se superponen con cero cuando la prueba es significativa).
Supuestos a verificar
Las pruebas t son pruebas paramétricas, lo que implica que podemos especificar una distribución de probabilidad para la población de la variable de la cual se tomaron las muestras. Las pruebas paramétricas (y no paramétricas) tienen varios supuestos. Si se violan estos supuestos, ya no podemos estar seguros de que la estadística de prueba siga una distribución t, en cuyo caso los valores de p pueden ser inexactos.
Normalidad. Para una prueba t pareada, se asume que la muestra de diferencias sigue una distribución normal. Si estas diferencias tienen una distribución muy sesgada, se pueden utilizar transformaciones para obtener una distribución más cercana a la normal.
Independencia. El diseño pareado tiene en cuenta que las dos medidas de cada par no son independientes. Sin embargo, es importante que cada par de objetos medidos sea independiente de otros pares. Si están relacionados de alguna manera (por ejemplo, grupos de plantas que comparten una bandeja de agua), puede ser necesario un diseño analítico más complejo que tenga en cuenta factores adicionales.
Comunicar los resultados
Escrito. Como mínimo, se deben informar la estadística t observada, el valor de p y el número de grados de libertad. Por ejemplo, se podría escribir “El rendimiento fotosintético de las plantas fue significativamente mayor en entornos soleados en contraste con los entornos sombreados (prueba t pareada: t = 18.81, df = 9, P < 0.001)”.
Visual. Los diagramas de caja o gráficos de columnas con barras de error son formas efectivas de comunicar la variación en una variable de respuesta continua en relación con un único predictor categórico.
boxplot(Performance ~ Treatment, data = Greenhouse, xlab = "Light environment", ylab = "Photosynthetic performance (FvFm)")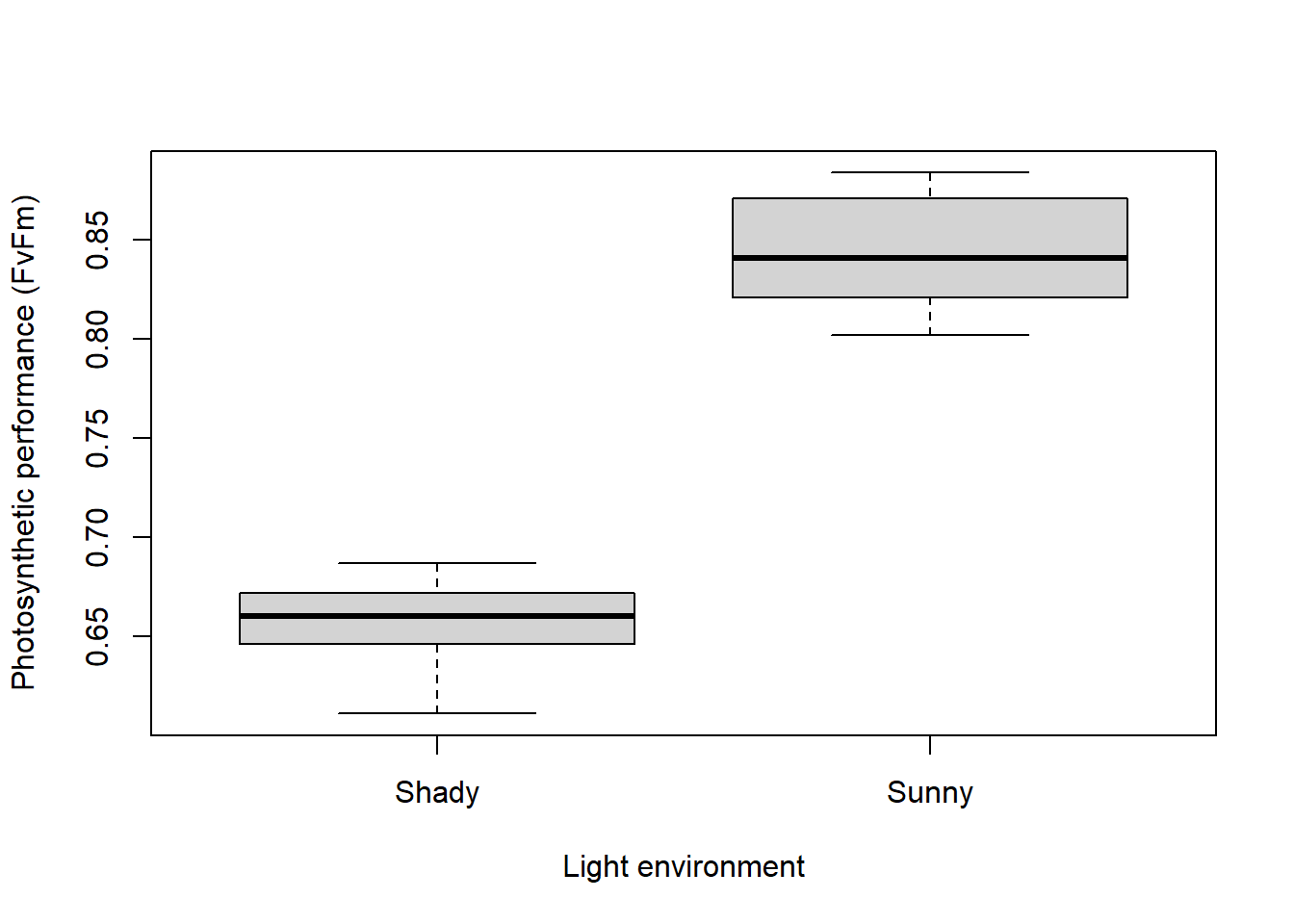
Más ayuda
Escribe ?t.test para obtener la ayuda de R sobre esta función.
Quinn y Keough (2002) Experimental design and data analysis for biologists. Cambridge University Press. Capítulo 9: Prueba de hipótesis.
McKillup (2012) Statistics explained. An introductory guide for life scientists. Cambridge University Press. Capítulo 9: Comparación de las medias de una y dos muestras de datos distribuidos normalmente.
Autor: Alistair Poore
Año: 2016
Última actualización: Ene. 2026